Complete data engineering tool kit with 200+ integrations. Superior features including an AI powered conversational Data Analytics agent - Neo



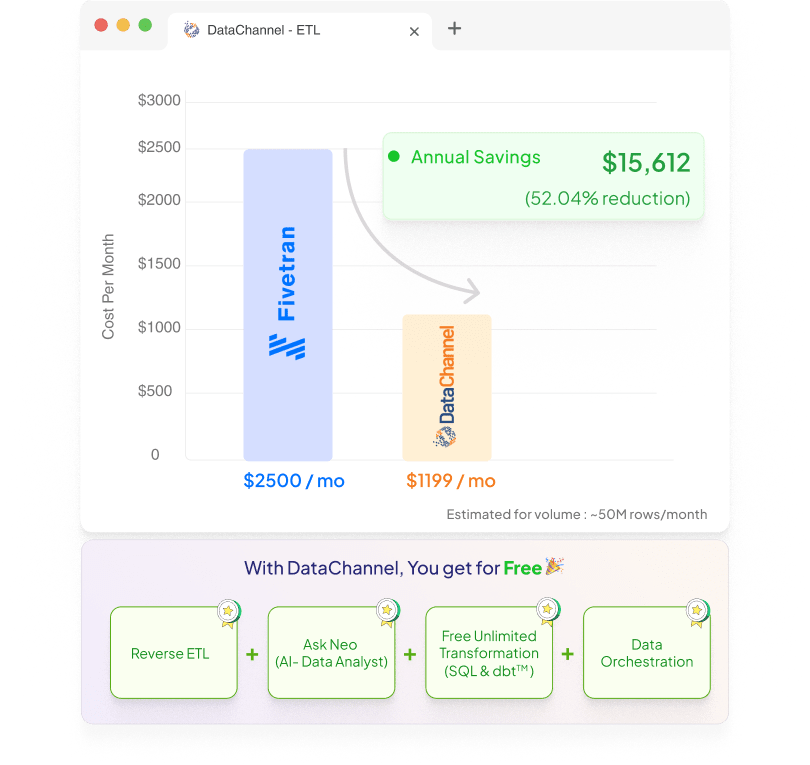














ETL & Reverse ETL in a single platform. Save upto 70% by replacing multiple tools with DataChannel


Move data in and out of your warehouse with a single, unified tool.
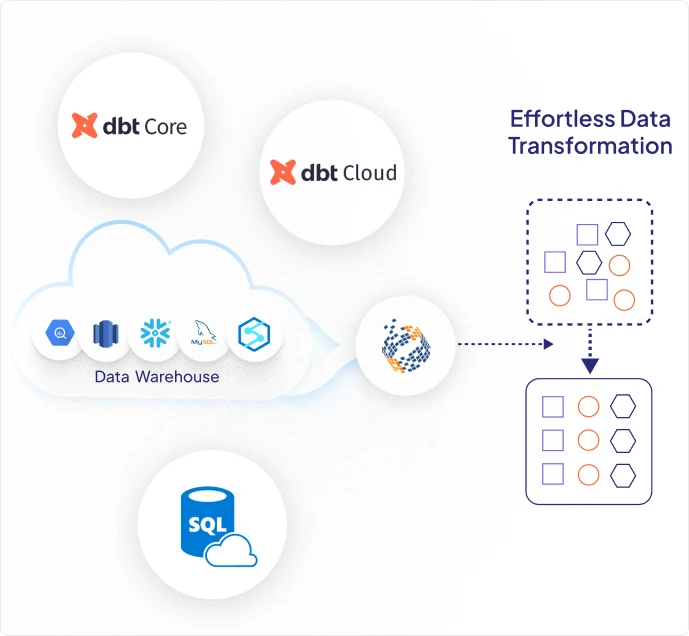
Support for SQL, dbtCoreTM and dbtCloud.
No limits on number of scheduled transformations

Using DataChannel’s Public Management API you can automate and manage critical tasks in every plan, at no extra cost.

Ask questions in plain English and get instant charts, dashboards, and insights.
Maintain granular access control and complete data security and compliance

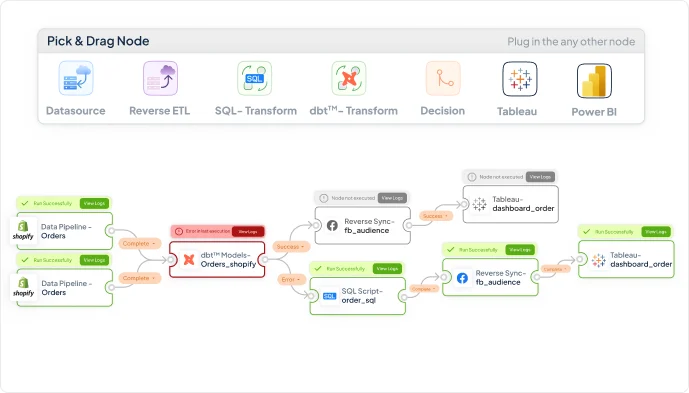
Design, schedule, and automate end‑to‑end workflows directly in the platform. No need for additional tools like Airflow

Connect to any available source or destination. No cap on connections. Transparent billing based on rows moved

Tell us your business‑specific connector needs—we build and maintain them for you.

Manage multiple organizations or teams under one account with isolated workspaces.

Pay only for the rows you move—no surprise platform fees.


Vast range of prebuilt connectors from SaaS platforms, databases, marketplaces, file sources etc. Built to move billions of rows at scale

Ask questions in plain English and get instant analytics, dashboards, and insights. Neo AI understands your data context and provides enterprise-grade analysis in seconds.

Easily schedule your SQL scripts and DBT models to run exactly when you want without ever leaving the platform
Visual DAGs, Build and visualize job dependencies. Schedule activations with dependency rules and retry logic.
Your data stays in your warehouse, fetched securely from your account with end-to-end encryption—DataChannel never stores it.


For Pro & Enterprise plan customers with direct access to your success manager.

Slack / email and on-call escalation for Enterprise customers.

Get expert on-boarding assistance to ensure your project is a definite success



Managing Director, Jump 450 Media
All we did was set up a few pipelines by entering our credentials and tweaking some source-specific parameters like breakdown criteria, frequency of update, etc. to suit our client’s needs, and that’s it. Now, thirty different sources are being automatically aggregated & delivered into our AWS Redshift warehouse, at a granularity and frequency of our choosing without us ever writing a single piece of code whatsoever.

"It has everything we need, from granular control over data we are integrating, to a quick turnaround time by the support team.”

"Our team simply loves DataChannel, it enables them to make data-driven marketing decisions and that too in real-time.”

"Prior to DataChannel, my team was deferring to manual reports, pivot tables, and built in dashboards on our advertising channels. Data Channel helped us save tons of time with the repetitive data download, cleaning, and aggregation."



