
Build vs.Buy Data Pipelines: A Detailed Discussion




Leaders let “DATA” decide, Laggards let intuition!
What color the new product packaging should be, or what age-group should be targeted in the next Facebook Ad campaign, more and more decisions are becoming data-dependent.
Businesses are spending millions of dollars in collecting, transforming, and analyzing more and minute “DATA” every year, in hopes of gaining access to crucial insights. With data pouring in from hundreds of sources every single day, manual integrations to fetch data become a burden on a firm’s assets. This is when organizations start looking into Automated Data Pipelines.
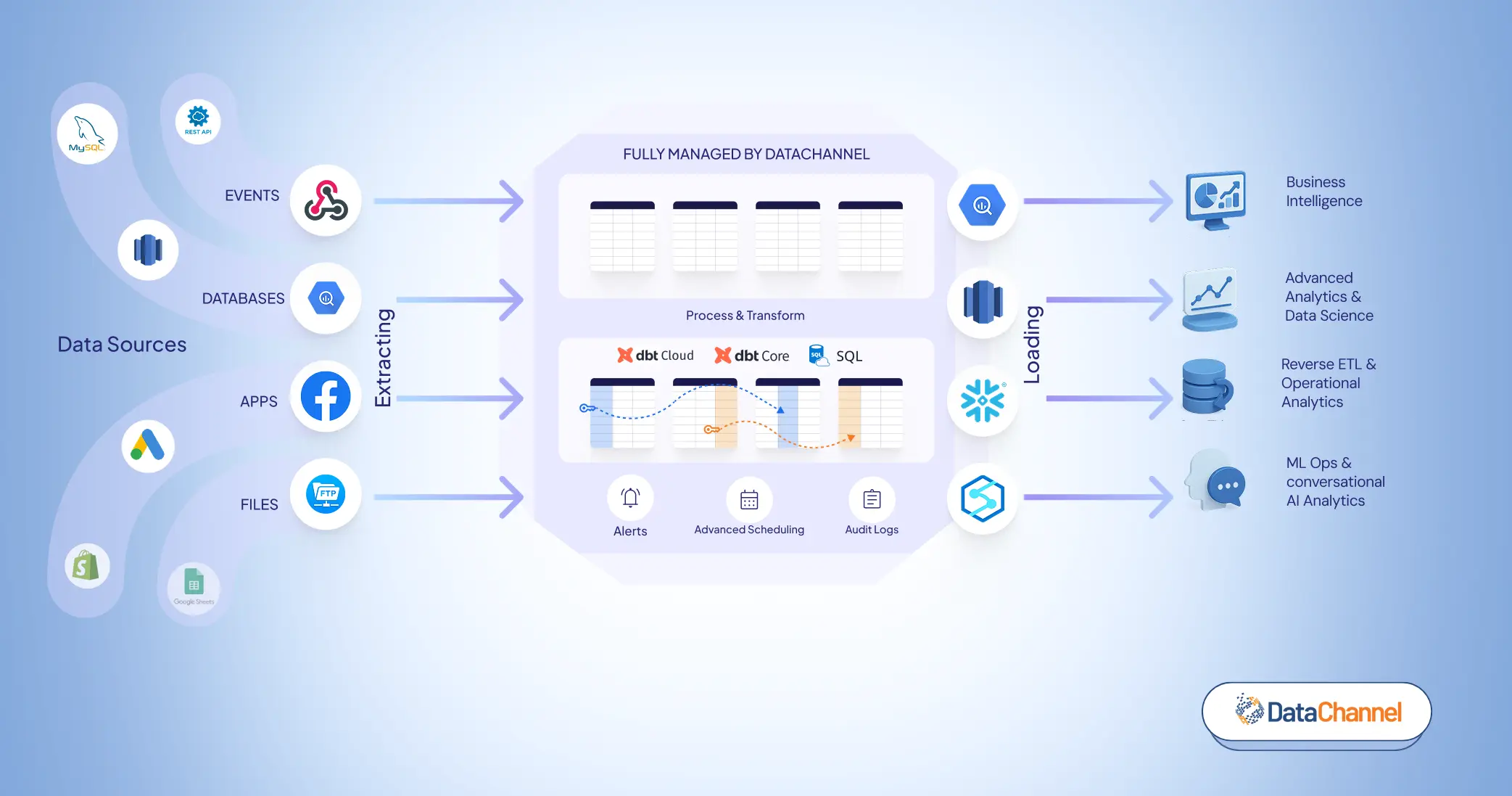
Automated Data Pipelines
In layman’s terms, a data pipeline constitutes a series of transformational steps that extract raw data from its source and enable its flow into an appropriate destination (likely to be a data lake or a data warehouse). During this journey, the data is filtered & transformed into a format that can be further used for analysis and reporting of crucial business insights. Data pipelines not only ensure a continuous and reliable flow of data into the various organizational storage and analysis subsystems but also monitor the data for accuracy and loss. The automated execution and monitoring of these data pipelines is typically handled by data orchestration tools. By employing a well-designed data pipeline, you can ensure access to relevant information in due time to make critical decisions for ensuring business’ success & survival.

Once you decide to incorporate data pipelines architecture into your data stack, the next obvious question is –
Which is better – Building data pipelines or Buying them?
The decision to build or buy a data pipeline depends on various factors, including the specific needs of the organization, the available resources (time, money, and personnel), and the level of customizations required.
While building a data pipeline from scratch may appear alluring and gives you full control & customization over the process, it can be time-consuming, repetitive and requires specialized technical expertise, as well as ongoing maintenance. A part of your data team will always be working to just keep the pipelines up & running as changes in system architecture, APIs, protocols, data governance requirements & technological changes will demand constant code updates.
Buying a data integration tool, on the other hand, is usually faster and requires much fewer resources. Choosing to buy a third-party ETL tool can be a more efficient and cost-effective option for organizations. It eliminates the need for in-house development and maintenance, freeing up valuable time and resources of your tech teams. With a wide range of pre-built solutions available, organizations can quickly implement a data pipeline that meets their specific needs, without sacrificing customization or control. Additionally, an automated process ensures that the organization benefits from regular updates and technical support from the vendor, reducing the burden on internal resources. Overall, buying a data pipeline is a smart choice for organizations looking to streamline their operations and reduce costs.

Let’s deliberate on a few key factors that can help you make the right decision for your organization.
Pocket friendly?
Most business decisions come down to choosing between a costly and a not-so-costly option, let’s discuss which data pipeline will be more budget-friendly for your business. To build a data pipeline from scratch, you will need a dedicated team of data engineers at your disposal and invest a substantial amount in purchasing and maintaining the technological infrastructure required to build. These days, a data engineer’s salary is easily upwards of 100k/year and you would require at least 4 to 7 of them for building and maintaining hundreds of data pipelines. On the other hand, the cost of buying an off-the-shelf data integration solution is only a fraction of what you invest in building data pipelines. For getting an accurate estimate of your data integration costs you can talk to the experts.

Time – Build vs. Buy
Building data pipelines is not a small feat. Generally, it takes somewhere between one to three weeks [Exact time depends on the source and the format in which it provides data] for a developing team to set up a single rudimentary pipeline. This includes time spent in building a capable team, getting the required technical infrastructure in place, and the actual building & testing time. Therefore, even if you choose to build data pipelines, it is probable that the deploying time will be nothing short of a few months if not years. Whereas, an off-the-shelf solution (Like DataChannel) reduces this time to only a few minutes. With DataChannel in place, you can immediately start leveraging insights.
Effort – Build vs. Buy
Building a data pipeline will require you to obtain developer access to diverse data resources (explicit permissions are sought for external sources and the source list would easily consist of 30+ sources for most firms), explore the data which would be handled by the pipeline, schema design, set up a connector framework, test and validate. Building a pipeline once might seem easy, its maintenance, however, is an indefinite endeavor. You have to be constantly vigilant for updates in the underlying data sources and once that happens, the above cycle repeats itself. All this amounts to wasted efforts in the long run, and it makes more sense to outsource data pipeline building and maintenance to a third party.
Customization? – Building pipelines makes more sense!
There is no doubt that every business requirement is unique and building in-house pipelines make more sense. Especially, when it comes to handling specific use cases, a vendor solution stands to disappoint you.
However, consider these –
- Most SaaS solutions have much deeper capabilities than you might be able to comprehend at an initial glance.
- The vendor has years of knowledge and experience in the field, a dedicated team of experts at his/her disposal, and he/she would be responsible for upgrades.
- Also, there exists an inherent bias against buying a SaaS solution instead of building one
Building pipelines is something you can always venture into, however, with so many customization options available in on-the-shelf solutions, you can always choose to opt for tailor-made data pipelines. Therefore, before closing doors on a third-party solution, give DataChannel a try. This way, you can be sure whether this solution adequately meets your requirement or you need to build your own data pipelines from scratch.
Scalability & Upgrades?
As consumers and marketing methods continue to evolve, new data sources will proliferate your business processes, necessitating their inclusion in your data source list. This will be highly beneficial for maximizing insight accuracy and reducing analysis errors. However, you will have no choice but to burden your data engineering team for integrating more and more data resources more often.
Even if you manage to handle that, events like frequent data source changes, the inclusion of new sources, unpredictable growth in amounts and variety of data, etc. will exhaust your team and burden your resources. Strategizing and planning for such events will be added to your to-do list as well. To summarise, it is conventional to outsource non-core functions such as data ETL and analysis, and you should benefit from the same.
With an off-the-shelf solution like DataChannel, you can expect infinite scalability options. Their team will be responsible for data source upgrades, source diversity, scalability, etc., all you need to do is use the derived insights.
What about issues like Reliability, Security, & Privacy?
For security and privacy reasons having complete control and visibility of your data is critical. Data will need protection from both internal and external threats like corruption, leaks, permission errors, etc. Therefore, building an in-house pipeline seems viable.
But consider this –
Now and then, data pipelines will suffer from issues like data delays, changing schema, changing volumes, pipeline failures, security & privacy breaches, incomplete transactions, etc., which can render the data useless or worse – harmful for your organization. The problem of maintaining data reliability, integrity, security, and privacy is a continuous and expert-level problem. Now, with your team engaged in core activities, you can not rely on their expertise, and their presence every single time such a problem comes up, and hiring a separate team for such purposes is not budget-friendly.
The middle path would be opting for an off-the-shelf solution like DataChannel, where their team is responsible for handling such issues and additionally they maintain strict adherence to international security and privacy guidelines.
Get the best of both worlds with DataChannel
Data is dear to businesses and it is important to deliberate well before choosing between building vs buying data pipelines for your organization. You can choose DataChannel to harness the power of big-data analytics by empowering your team with the DATA that is logically linked, frequently updated, and automatically maintained into a warehouse of your choice with the help of their pre-built 100+ data pipelines.
Let us look at some of the features offered by DataChannel, in light of what we discussed above.
- 100+ Data Sources. DataChannel’s ever-expanding list of supported data sources includes all popular advertising, marketing, CRM, financial, and eCommerce platforms and apps along with support for ad-hoc files, google sheets, cloud storages, relational databases, and ingestion of real-time data using webhooks. If we do not have the integration you need, reach out to our team and we will build it for you for free.
- Powerful scheduling and orchestration features with granular control over scheduling down to the exact minute.
- Granular control over what data to move. Unlike most tools which are highly opinionated and dictate what data they would move, we allow you the ability to choose down to field level what data you need. If you need to add another dimension or metric down the line, our easy to use UI lets you do that in a single click without any breaking changes to your downstream process.
- Extensive Logging, fault tolerance and automated recovery allows for dependable and reliable pipelines. If we are unable to recover, the extensive notifications will alert you via slack, app and email for taking appropriate action.
- Built to scale at an affordable cost. Our best in class platform is built with all ETL best practices built to handle billions of rows of data and will scale with your business when you need them to, while allowing you to only pay for what you use today.
- Get started in minutes. Get started in minutes with our self-serve UI or with the help of our on-boarding experts who can guide you through the process. We provide extensive documentation support and content to guide you all the way.
- Managed Data Warehouse. While cloud data warehouses offer immense flexibility and opportunity, managing them can be a hassle without the right team and resources. If you do not want the trouble of managing them in-house, use our managed warehouse offering and get started today. Whenever you feel you are ready to do it in-house, simply configure your own warehouse and direct pipelines to it.
- Activate your data with Reverse ETL. Be future-ready and don’t let your data sit idle in the data warehouse or stay limited to your BI dashboards. The unidimensional approach toward data management is now undergoing a paradigm change. Instead, use DataChannel’s reverse ETL offering to send data to the tools your business teams use every day. Set up alerts & notifications on top of your data warehouse and sync customer data across all platforms converting your data warehouse into a powerful CDP (Customer Data Platform). You can even preview the data without ever leaving the platform.

Editor’s Note
It is unwise to use a sword in place of a needle. You have a lot on your plate already, and building data pipelines will require a great deal of effort, time, money, and experience.




Try DataChannel Free for 14 days
