
ETL vs ELT: What is the Best Approach for your Data Warehouse?




ETL vs ELT: What is the Best Approach for your Data Warehouse?
Business organizations today are handling large volumes of data which are scattered across different formats. Whether your data warehouse is using a structured SQL database or an unstructured format, most information sources mostly use compatible formats. Therefore, before integrating your data into an analyzable format, you will have to clean, enrich, and transform all your data sources.
To accomplish the above\, most data warehouses use either of the following methods:
- ELT (extract, transform, load)
- ETL (extract, load, transform)
While ETL is the traditional method of data warehousing, ELT is also used commonly these days,
Regardless of whether it is ETL or ELT method, the data integration process has these three essential steps:
- Extract – refers to the process of retrieving raw data from an unstructured data pool. In the ETL method, this raw data is extracted into a temporary staging data repository and in the ELT method, it is extracted into the storage system of the data lake.
- Transform – refers to the process of restructuring and enriching of raw data so that it can be integrated with the target source data.
- Load – refers to the process of loading the structured data into a data storage system to be used by BI tools, such as Tableau, Looker, and Zoho Analytics.
The main difference between the two methods is that ETL includes a staging area for implementing data transformation.
So, to understand which approach is better for your data warehouse, It;s important that we understand each method in detail.
What is ETL?
In ETL, the data is first extracted from homogeneous or heterogeneous data sources, and then deposited into a staging area – after which it gets cleaned, enriched and transformed to the required data format. And finally, it is uploaded to the data warehouse. ETL is an essential component of Online Analytical Processing (OLAP) based data warehouses such as IBM Cognos, SAP NetWeaver, Microsoft Analysis Server, Jedox OLAP Server. As OLAP only accepts structured data, your data must be transformed before the loading part. Traditional ETL methods were time-consuming with a waiting period for the data to go through each stage. However, modern cloud-based ETL solutions are much easier and faster.

What is ELT?
In the ELT method of data extraction, after the data is extracted, you can directly start the loading process and move the data into the repository. There is no need to move the data into a temporary staging area. Data transformation then happens within the target database.

The ELT process works for data lakes that unlike OLAP data warehouses accept both structured and unstructured data. This means there is no mandate of transforming the data before loading it.
ETL and ELT – An example using Microsoft Azure
Now that we know what ETL and ELT mean, let us see an example of how a typical ELT and ETL workload can be implemented using Microsoft Azure.
Example 1 of an ELT pipeline
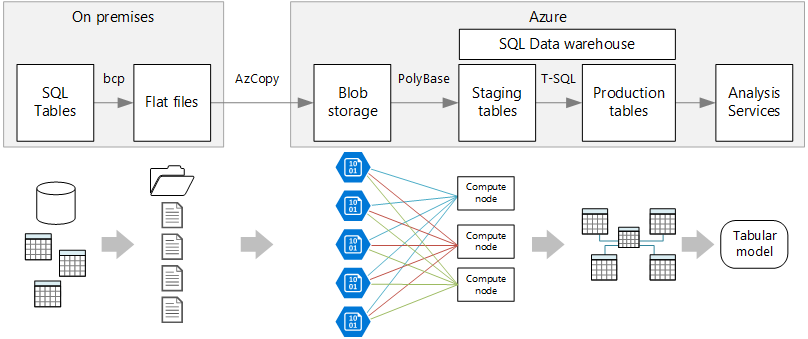
A business organization with OLTP dataset stored in SQL Server database using Microsoft Azure Synapse tool to perform data analysis and visualization using Power BI.

Here are the various stages of the data pipeline using ELT:
- Exporting the source data from SQL Server to flat files using bcp (or bulk copy) utility.
- Copying the flat files into Azure Blob Storage that serves as the temporary staging area.
- Loading the data into Azure Synapse.
- Transforming the data is transformed into a star schema – suitable for semantic modelling.
- Loading the semantic model into SQL Server Data Tools.

Example 2 of an ETL pipeline
It acquires data from various sources and orchestrates the ETL jobs using MS Azure HDInsight tool.
Orchestration is necessary to ensure that the required job runs at the appropriate time. Here are the various stages of the data pipeline using ETL:
- Ingest the file and result storage using Azure Storage or Azure Data Lake Storage repository.
- Extract and load the existing data in Azure using services such as Apache Sqoop or Apache Flume.
- Transform the data for preparation using HDInsight-supported tools like Apache Hive, Apache Pig, or Spark SQL.
ETL vs ELT – A comparison chart

ETL or ELT: Which is right for data warehousing?
How does ELT score over ETL – when it comes to data warehousing? Here are few of its advantages:
- Flexibility and ease of storing raw and unstructured data.
- Immediate access to all the information without the mandate of transforming and structuring it first.
- High speed of data ingestion, without any heavy lifting by the data pipeline.
- Faster loading time and low-maintenance , making ELT ideal for companies regardless of the volume of their data.
So, in which cases you should consider using ELT instead of ETL? Here are some of the prototype cases:
USE CASE #1: Companies with massive amounts of data
ELT is a better solution for managing massive amounts of structured and unstructured data. With cloud-based ELT solutions, you can process large volumes of of data quickly
USE CASE #2: Companies that need immediate data access
ELT is also preferred when you need instant access to data. As transformation is the last step, ELT prioritizes fast loading of its data to the data repository.
DataChannel – An integrated ETL & Reverse ETL solution
- 100+ Data Sources. DataChannel’s ever-expanding list of supported data sources includes all popular advertising, marketing, CRM, financial, and eCommerce platforms and apps along with support for ad-hoc files, google sheets, cloud storages, relational databases, and ingestion of real-time data using webhooks. If we do not have the integration you need, reach out to our team and we will build it for you for free.
- Powerful scheduling and orchestration features with granular control over scheduling down to the exact minute.
- Granular control over what data to move. Unlike most tools which are highly opinionated and dictate what data they would move, we allow you the ability to choose down to field level what data you need. If you need to add another dimension or metric down the line, our easy to use UI lets you do that in a single click without any breaking changes to your downstream process.
- Extensive Logging, fault tolerance and automated recovery allows for dependable and reliable pipelines. If we are unable to recover, the extensive notifications will alert you via slack, app and email for taking appropriate action.
- Built to scale at an affordable cost. Our best in class platform is built with all ETL best practices built to handle billions of rows of data and will scale with your business when you need them to, while allowing you to only pay for what you use today.
- Get started in minutes. Get started in minutes with our self-serve UI or with the help of our on-boarding experts who can guide you through the process. We provide extensive documentation support and content to guide you all the way.
- Managed Data Warehouse. While cloud data warehouses offer immense flexibility and opportunity, managing them can be a hassle without the right team and resources. If you do not want the trouble of managing them in-house, use our managed warehouse offering and get started today. Whenever you feel you are ready to do it in-house, simply configure your own warehouse and direct pipelines to it.
- Activate your data with Reverse ETL. Be future-ready and don’t let your data sit idle in the data warehouse or stay limited to your BI dashboards. The unidimensional approach toward data management is now undergoing a paradigm change. Instead, use DataChannel’s reverse ETL offering to send data to the tools your business teams use every day. Set up alerts & notifications on top of your data warehouse and sync customer data across all platforms converting your data warehouse into a powerful CDP (Customer Data Platform). You can even preview the data without ever leaving the platform.






{kind=link}
Try DataChannel Free for 14 days
