
ETL Best Practices: Complete guide for Data Engineers




Table of Contents
- What is ETL?
- Challenges in setting up a reliable & scalable ETL process
- Best practices for setting up ETL data pipelines
- How can DataChannel help you in setting up a scalable & reliable ETL process?
What is ETL?
Use of multiple SaaS apps and cloud native tools is now ubiquitous across all modern businesses. The productivity gains are undeniable and the ability of businesses to respond with agility to ever-changing situations enhanced significantly with these tools. These gains, however, come with a hidden peril of mountains of data generated across all these platforms in addition to the company’s core operational systems. The problem becomes more pronounced with any business having a significant E-commerce footprint as crucial data related to inventory, orders, shipping, fulfillment, returns, invoices, compliances and so on is stored in different places / applications / marketplaces. These data storages often end up becoming inert data silos, restricting access and data visibility across business functions. Left unaddressed, these data silos now start adversely impacting the businesses. In short, the solution itself tends to aggravate the problem it sought to eliminate.
According to a Forbes report, “due to data silos, improved understanding and management of data would demand an additional 50% of the budget by the years 2019–21.”
The solution to the data silo problem is self-evident and largely known; have a master repository of all the data accumulated across all the platforms, frequently updated and correctly formatted, as a single source of truth. All business functions can then access this repository and take synchronous business decisions. A cloud-native Data Warehouse or a Data Lake are the natural choices when it comes to secure, responsive, and accessible data repositories of this nature. With the advent of cloud data warehouses like Amazon Redshift, Google Bigquery & Snowflake etc, it is now not just cost effective but also accessible to companies of all sizes to set this up. However, setting up these data stores is futile if the information in them is not kept current, accessible and in a format suitable for downstream consumption.

This is where ETL (Extract, Transform & Load) as a process comes into play. The smooth & uninterrupted flow of data from a data source (any SaaS app / platform) to the intended data warehouse in the correct format is what any ETL process ideally aims to achieve. The industry tends to label the series of steps to achieve this goal as setting up an ETL pipeline analogous to an actual pipeline. However, setting up ETL systems and pipelines is not a simple task due to the inherent challenges of handling multiple data sources each with their own APIs, authentication systems, data formats, rate limitations etc coupled with continually changing business requirements and needs.
Today, enterprises look for ETL solutions that offer flexibility with data sources & warehouses, scheduling, not to mention a quick turnaround time, control over granular data, and scalability within the infrastructure.
So, the problem is well defined and the solution obvious, however, as it is often with modern technology, the solution encapsulates several tricky challenges. In the subsequent paragraphs we will look at some of them and recommend the ETL best practices to overcome these challenges.

Challenges in setting up reliable & scalable ETL processes
Setting up ETL systems and pipelines is a complex undertaking and has multiple challenges. Some of them are:-
- Vast number of disparate data sources. A classical problem of plenty as today any company, even small to midsize companies are typically working with at least 7-8 different SaaS applications, have their marketing data in different ad platforms and eventually end up needing to move data from 10-12 different data sources each with their own APIs, data formats, protocols, rate limitations any other rule which catches the platform creator’s fancy.
- Granular control over data being extracted from the sources. Each data source may be exposing a lot of information, some of which may not be useful or may be of a sensitive nature like Personal Identifiable Information (PII) storing which in the data warehouse or data lake may introduce new regulatory complexity / challenge, hence the ETL systems need to have ability to granularly control what information is being extracted from the source. Moreover, transferring all the fields available all the time would incur substantial computational costs.
- Reliability & Fault Tolerance. Once we set up ETL pipelines and there are downstream systems set up where this information is being utilized for day-to-day functioning and decision making, the data integrity and freshness becomes vital. Hence, the pipeline setup must be reliable, fault tolerant and capable of self-recovery. Designing such systems needs a high degree of technical skill, time, and resources.
- Scalability. Global data growth has been explosive therefore, any ETL systems need to be highly scalable. Even if in the beginning you are expecting a low volume of data, as your company grows, the data volume will grow exponentially. Additionally, new platforms and data sources will need to be integrated into the system all the time. Designing ETL systems which can scale with your requirements would again need substantial technical expertise and bandwidth, not to mention expensive hardware resources.
- Constantly evolving business requirements. As the downstream business teams start employing data to take day to day decisions, their requirements will evolve and the data teams are constantly flooded with requests for more information, adding new metrics, KPIs, providing a different cut / view of the data, all of which keeps the data teams incessantly drowned in drudgery, which is not only not their core job, but also quickly becomes monotonous and tedious.
- Constant changes to source APIs / source schema. As the source systems evolve, add new features / functionalities, or adopt new technologies, their APIs evolve, requiring cascading changes to the ETL process. Thus, designing the ETL process is not a one-time engineering effort, but needs regular updates and maintenance. Unless designed with software best practices in mind, this is a herculean effort. This approach is not evident to data engineers who want to work on data to generate insights rather than write mundane code with multitude of platform specific constraints to move data.
- Handling ad-hoc data formats and sources. While most systems would have APIs to integrate with, there always would be requirements to ingest data from spreadsheets, CSV files or dumps of json data from files, cloud storages like S3 etc which make the entire process error prone and manual.
- Keeping up with the timelines set by Business Teams. Data teams are constantly under pressure to deliver the required data to the business teams at the earliest possible time and never have enough time to set up pipelines which can follow all the best practices, thus leading to unreliable ad hoc systems. The result is error prone ETL pipelines providing incomplete and stale data, disappointing the business teams.
- High data transformation requirements and complexity. Most data teams end up underestimating the need for data transformation while conceptualizing the ETL process. Every source system will give data in different formats which would need to be transformed to be of actual use by downstream systems. All of this is not just time consuming but also requires significant resources which need to be catered for at the design stage itself. Also, prior planning for what kind of transformation can be done prior to loading data and what needs to be done after the data lands in the data warehouse is critical.
11 ETL Best Practices for setting up data pipelines
While the challenges listed above are very real and may seem difficult to overcome, following the ETL best practices listed below can help you in mitigating their effect to a large extent.
- Understanding the business needs and source systems in detail. Before we design our ETL process, getting a clear understanding of what information the source systems provide and what is required by the business teams and doing a thoughtful gap analysis is extremely critical to the success of these initiatives. The compromises required, if any, at this stage would be much easier to alleviate than to have a situation of gross expectation mismanagement.
- Understanding the architecture of the source APIs and their upgrade cycle. Before we start planning the extract step, getting a clear understanding of the API of the source, the type and format of data it provides as well as their update and release schedule, frequency of updates and breaking changes introduced with updates needs to be thoroughly analyzed. Availability of official SDKs in the language you use for development can really help in faster development & setup. Some more aspects of the API which merit attention are:-
- Authentication mechanisms.
- Expected parameters and their formats.
- Requirements of access rights and the approval process for getting these access rights.
- Rate limits / limits of amount of data you can extract.
- How to get / load historical data?
- Granular selection of data to extract. While it may be easier and tempting to just get everything the source has to offer, this brute force approach will eventually create more problems than it will solve. So, always plan / design to have granular control over what data you are moving from the source systems. Any future compliance / PII requirements as well as data security will automatically be addressed by this process. Additionally, wanton waste of computational resources and allied costs can also be prevented.
- Modular design. Modularization is the process of breaking the entire system into smaller reusable blocks. These would allow you to not only have reusability of code but would also create error or fault boundaries and allow for easier unit testing. Modularity also begets inherent advantages of scalability and effective resource management.
- Fault tolerance. With modular design and error boundaries, you also need systems to detect faults and errors and try to recover gracefully from them. All ETL processes involve a lot of different systems and at times errors are transient in nature like network issues between source and destination which can be recovered from with an exponential back off and retry strategy. If, however, the fault persists, there should be a way to log and notify the error to the relevant stakeholders.
- Extensive Logging. As mentioned above, ETL systems are complex and involve a lot of moving parts and steps. This makes it difficult to debug them if the logging is insufficient or not in a clear understandable format. Always err on the side of logging extra while being careful not to log any sensitive data or information.
- Audit logs for all changes. As teams grow and the requirements evolve, multiple people would be making changes to the pipeline setup. It is imperative that all these changes are audited and logged so that when some code breaks, we can trace it back to the change and take corrective action.
- Retain copies of source data which you fail to load due to errors. At times the source systems, especially event sources only send out the information once. If there is an error after the information is received and before it can be loaded into the destination system there are chances of data loss unless this data is also retained in the raw format so that it can be later processed either manually or through an alternate recovery system.
- Design for the future scale & size of data. While designing systems use practices like parallel processing, auto scaling etc even if your data size currently does not require them as inevitably the requirements would arise as your business grows. The inflexion point for rapid scale is not predictable, thus poor planning at the initial stage would hurt business growth later.
- Choose a flexible orchestration and scheduling engine. ETL systems have several moving parts and interdependent steps which need to be orchestrated and scheduled with granular control to distribute load over time and ensure data is fresh and ready when needed. Choosing / designing a scalable and flexible engine for this is critical to the success of these initiatives. Innocuous details like different time zones, business hours and backup schedules if ignored often cause inexplicable failures which are very difficult to trace.
- Exploit the power of cloud data warehouses for transformation. Today’s data warehouses offer very cost effective but highly powerful data processing options which can scale to terabytes without any effect on their performance. We should plan to push down transformation steps to the warehouse wherever possible to take advantage of their immense power. It also allows us to use SQL (Structured Query Language) which is one very easy and flexible to design our transformation steps.
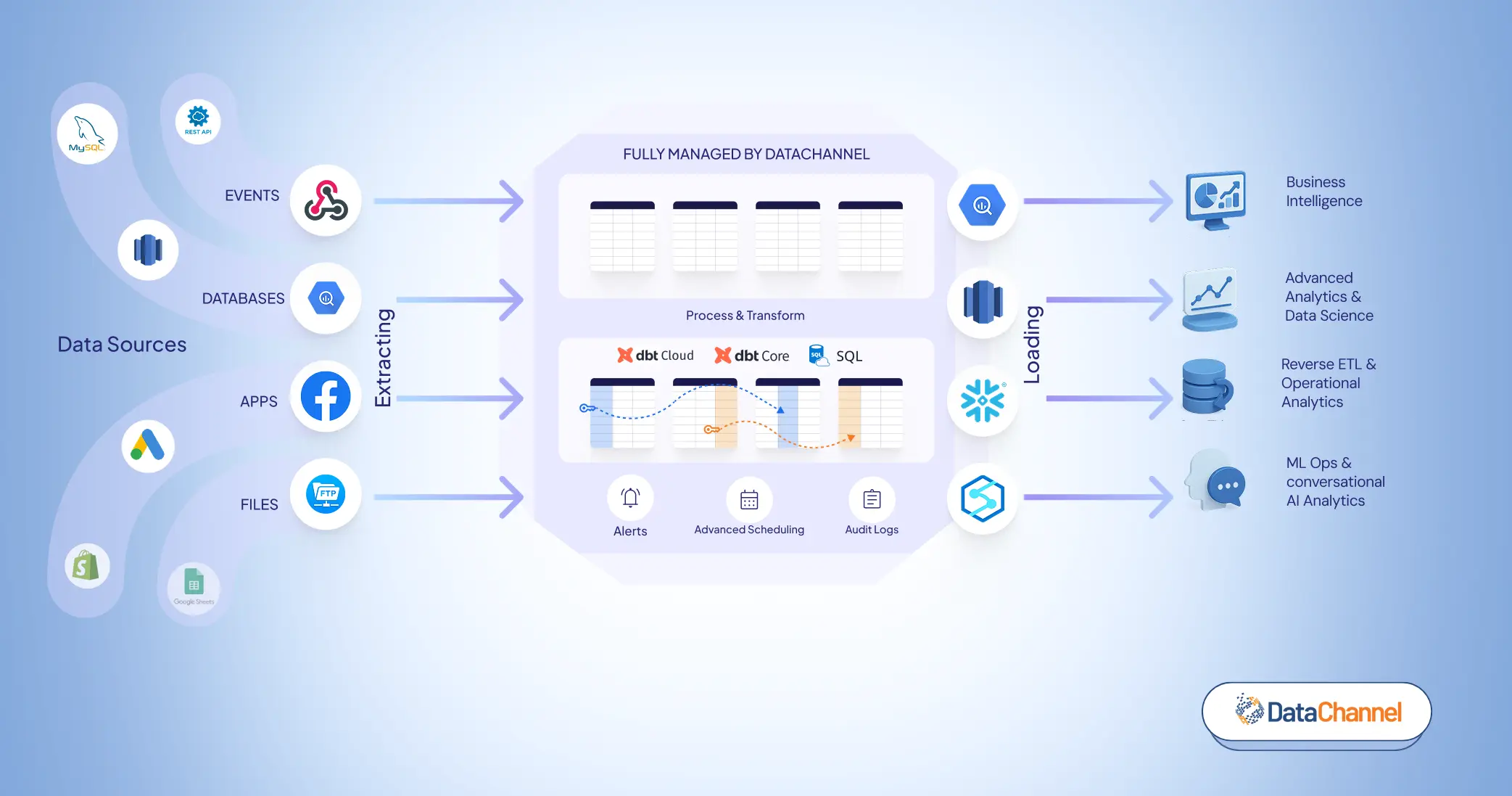
DataChannel – An integrated ETL & Reverse ETL solution
- 100+ Data Sources. DataChannel’s ever-expanding list of supported data sources includes all popular advertising, marketing, CRM, financial, and eCommerce platforms and apps along with support for ad-hoc files, google sheets, cloud storages, relational databases, and ingestion of real-time data using webhooks. If we do not have the integration you need, reach out to our team and we will build it for you for free.
- Powerful scheduling and orchestration features with granular control over scheduling down to the exact minute.
- Granular control over what data to move. Unlike most tools which are highly opinionated and dictate what data they would move, we allow you the ability to choose down to field level what data you need. If you need to add another dimension or metric down the line, our easy to use UI lets you do that in a single click without any breaking changes to your downstream process.
- Extensive Logging, fault tolerance and automated recovery allows for dependable and reliable pipelines. If we are unable to recover, the extensive notifications will alert you via slack, app and email for taking appropriate action.
- Built to scale at an affordable cost. Our best in class platform is built with all ETL best practices built to handle billions of rows of data and will scale with your business when you need them to, while allowing you to only pay for what you use today.
- Get started in minutes. Get started in minutes with our self-serve UI or with the help of our on-boarding experts who can guide you through the process. We provide extensive documentation support and content to guide you all the way.
- Managed Data Warehouse. While cloud data warehouses offer immense flexibility and opportunity, managing them can be a hassle without the right team and resources. If you do not want the trouble of managing them in-house, use our managed warehouse offering and get started today. Whenever you feel you are ready to do it in-house, simply configure your own warehouse and direct pipelines to it.
- Activate your data with Reverse ETL. Be future-ready and don’t let your data sit idle in the data warehouse or stay limited to your BI dashboards. The unidimensional approach toward data management is now undergoing a paradigm change. Instead, use DataChannel’s reverse ETL offering to send data to the tools your business teams use every day. Set up alerts & notifications on top of your data warehouse and sync customer data across all platforms converting your data warehouse into a powerful CDP (Customer Data Platform). You can even preview the data without ever leaving the platform.





Try DataChannel Free for 14 days
